Back!MyBDer
问题1:什么是面向对象?
对比面向过程、面向对象和面向函数三种处理问题的角度
面向过程更注重事情的步骤,面向对象更注重事情的参与者,面向函数更关注其中的运算
比如:洗衣机洗衣服
面向过程编程会按照步骤一步步执行:人打开洗衣机,放衣服,放洗衣服,洗衣机清洗,烘干…
面向对象编程会分成两个对象,人做什么,洗衣机做什么
面向函数编程更在乎行为:最外层是operate(process),process传入洗衣服wash(clothes,methods),methods再传入具体的清洗方法
面向对象和面向函数都能够复用代码
封装、继承、多态
封装:封装的意义:内部对外未黑盒(透明)、外部暴露允许访问的成员函数和数据项
类的封装:经典操作提供private数据的getset方法,就是将数据的赋值和获取逻辑把握在自身| 可能要求名字共同前缀 or其他限制。
框架的封装:例如ORM框架mybatis,开发者只需要利用mybatis特定方法即可实现功能,不需要关心/不允许修改实现逻辑
继承:继承基类的方法,并作出自己的改变或扩展
多态:
父类和多个子类:
基于对象所属类的不同,外部对同一个方法的调用,实际执行的逻辑不桶
多态的三要素:继承/实现、方法重写/实现、父类引用指向子类对象
抽象类和多个实现类:
一个抽象类引用某个实现类的方法,本质上还是实现类对象调用其方法
一个实现类可用实现多个接口,它就是多个抽象类的实现,对外可被看作是多种状态 – 多态
问题2:JDK、JRE、JVM
JDK:java Development Kit Java开发者工具
JRE:java Runtime Environment Java运行环境
JVM:java virtual machine
下载JDK包含JRE文件夹,JRE中有两个关键文件夹:bin(JVM)、lib(类库)
JDK除JRE外提供的开发工具:javac,java,jconsole,jmap…
问题3:== 和 equals
equals如果没有重写的话,在Object类中的equals本质就是 == 比较
== 比较的内容:对于基本数据类型,由于其数值保存在栈内存中,直接比较数值
对于引用数据类型,其比较的是对堆内存的对象的引用地址
equals通常都会重写,在String中的重写是将字符串转化成char数组后挨个比较
但对与字符串特殊的一点在于:字符串常量池
JVM为了提高性能和减少内存开销,在实例化字符串常量时,为字符串开辟了一个缓存区 - 常量池
内部本质上维护了一个table,是字符串对字符串对象的引用
1 | |
此方法会优先去常量池中看看有无此引用,若有直接使用这个引用,若无则创建对象放入常量池中
1 | |
此方法会创建一个新的对象,在堆内存中常量池外,但也会保证创建的对象在常量池中有副本
即:若常量池中没有此字符串,则会在常量池和堆内存中各创建一个,这两个对象中byte[]使用的是同一个
对其他基本数据类型的包装类也有特殊的点:都有常量池的思想(除了float和double)
对于int和int,int和Integer之间都只是基本的数值比较,因为int的值都在栈内存里,int和Integer比较的话Java会自动将Integer拆箱成int
但对于Integer和Integer的比较,Java维护了 -128到127之间的常量池,内部的Integer引用同一个对象;为什么不把这些Integer也自动都拆成int然后比较呢?毕竟拆箱本身没什么成本
尤其是装箱,如果Integer常量池没有的话需要返回new的对象,而且不会把新对象加入池子中拆箱本身没有什么成本,就是返回Integer中的value
Integer提供了重写的equals方法,内部就是判断各自的value是否相同
感觉可能是Java为了向后兼容 or else;
问题3:说说字符串常量池
JVM为了提高性能和减少内存开销,在实例化字符串常量时,为字符串开辟了一个缓存区 - 常量池
内部本质上维护了一个table,是字符串对字符串对象的引用
三种字符串操作:
“+”连接字符串
普通常量连接:
1
String s = "a"+"b"+“c”;Java编译器会将其自动视为
1
String s = "abc";字符串变量之间的连接:
1
2
3
4
5String a = "a";
String b = "b";
String c = "c";
String s = a + b + c;由于Java中String是不可变类型,所以以上连接会被反编译成
1
(new StringBuilder()).append(a).append(b).append(c).toString();toString中,返回一个new的字符串对象
intern()方法: —— 作用是对字符串对象规范表示 / 标准化 – 统一从池子里拿
当调用intern方法时,首先判断常量池中是否存在相同值的字符串常量,如果存在则返回常量池中的字符串的引用,如果不存在,则会在常量池中增加一个相同的字符串常量,返回在常量池中的引用;
问题4:你懂final吗?
final的用法:
- 修饰类:表示类不可被继承
- 修饰方法:表示方法不可被子类覆盖,但是可用重载(改变参数 / 返回值的新方法可存在)
- 修饰变量:表示变量一旦被赋值,就不可被修改
final修饰变量的初始化时机 – 都要求刚刚加载时完成初始化:
Java会给每个成员变量赋默认值初始化,但不会给局部自动变量初始化
final修饰成员变量:
- 如果是static的,只能在声明时或者静态代码块中初始化
- 如果是普通成员变量,只能在声明时或者非静态代码块中(或者构造器中)初始化
final修饰局部变量:
局部变量可以在声明时指定值,也可以不指定,在后续代码中完成对final的赋值。
因为不加final声明时本身也不会初始化
final修饰基本数据类型和引用数据类型
- 基本:数值在初始化后就不可被修改
- 引用:引用在初始化后就不能再让其指向另一个对象,但引用的值是可变的
为什么局部内部类和匿名内部类只能访问final变量?
问题描述:局部内部类和匿名内部类如果想要访问调用方法中的局部变量时,只能读,不能赋值 | 如果想要赋值只能转化成数组[0] —- 隐式的final修饰
内部类理应可以访问外部的局部变量,但有一个问题:外部方法结束后会销毁局部变量的,这就会导致内部类引用了空的内容;
最常见的情况就是用匿名内部类开新线程,新的线程可能需要长时间引用某个变量,但外面的方法早就执行完了会自动回收变量。
解决方案是:将局部变量复制了一份作为内部类的成员变量,内部类实际访问的是局部变量的副本。新的问题是:副本是两个不同的数 / 对象,修改其中一个没法自动修改另一个;所以Java的妥协就是 - 不能修改,只能读取 - 来保证内部类的成员变量和外部方法的局部变量是一致的。
问题5:String、StringBuffer、StringBuilder
String是final修饰的不可变类型
StringBuffer是线程安全的,StringBuilder是线程不安全的
线程不安全:多线程环境下存在共享变量,需要额外加锁才能避免竞态问题
StringBuffer中每个方法都写好了synchronized
使用场景:
优先使用StringBuilder(由于没有锁性能较好),但是当变量是在多线程环境下的共享变量,使用StringBuffer
同时由于以上二者操作是对同一个对象,而不会想String一样每次操作产生新String
问题6:重载和重写的区别
重载:在同一个类中,方法名相同,参数类型不同、个数不同、顺序不同、返回值不同、修饰符不同等等方法间构成重载,但需要让调用者能够区分调用的是谁(只有访问修饰符或者返回值不同不行)
重写:发生在父子类中,方法名、参数列表必须相同;访问修饰符需要大于等于父类。但如果父类是private修饰则不能被重写
重写方法返回值范围小于等于父类(是父类返回值的类型或其子类);抛出的异常范围小于等于父类(..其类型或其子类) —- 由于在多态时,子类向上返回的值 / 抛出的异常可以被父类对象的上下文兼容;
问题7:接口和抽象类的区别
接口的设计目的:是对类的行为进行约束(让类具有某种能力)
接口是对行为的抽象 - - 符合 like a 的关系
抽象类的设计目的是代码复用。当不同的类具有某些相同的行为时,这些行为可以抽离成一个抽象类 - 其中某些代码(方法)是复用的,其他子类们不同的方法定义成抽象方法
抽象类的本质是对子类们的抽象 - - 符合 is a 的关系;
但是抽象类的成本比较高,因为一个类只可以继承一个类。当比较关注类的本质时可以用抽象类;接口虽然在功能上弱化了许多,它只实现了对动作的描述,但一个类可以实现多个接口,更灵活点。在关注类的行为时用接口;
问题8:hashCode and equals
重写equals是为了准确判断两个对象是否相等,但在Java的集合框架中,当用到hash来判断某个元素是否存在于某个集合中时,使用计算hashcode后在hashTable中比较,来代替O(n)级别的equals方法。所以和重写equals的目的一致,重写hashCode也是为了在通过计算哈希值判断是否是同一个元素的场景下,能够准确判断
原本计算hashcode是基于内存地址的,不同对象就算在像也不会有一致的hashcode
hash的具体判断:例如HashSet,HashSet会先计算对象的hashCode来判断对象加入的位置,如果该位置有值,为了防止是哈希冲突嘛,再调用equals判断两个对象是否真的相同。
问题9:ArrayList and LinkedList
ArrayList:基于动态数组,底层是连续的内存空间,每个元素由于泛型限制占的空间一致,所以只需要开始位置和偏移量即可访问 – 适合下标访问。
但也因为本身是连续的空间,导致插入删除的成本比较高,往往需要平行移动一部分元素。但有一种场景是这样:并不关心List内部的顺序,所以用尾插法就可以很快的插入,此时效率很高。
同时当数据长度越来越长,会逐渐超过内存空间,于是需要再复制到更大的空间。
扩容太频繁也会对代码整体性能产生影响,一般在ArrayList初始化时指定长度就号
LinkedList:本身基于链表,可以分散的存储在内存中,适合做数据的插入和删除操作;相对的就不适合查询;遍历时避免用for循环根据索引来查找(因为每次查找都需要从头来);
并且LinkedList将元素包了一层node,对内存而言也比较有压力。
问题10:哈师卖
hashTable相比hashMap,在每个方法上都加了Synchronized确保线程安全
hashMap在多线程场景下可能出现竞态问题导致数据前后不一致;
HashMap运行key和value为null,但hashTable不允许
底层!
数组+链表
一点思考:
为什么索引都是从0开始的,因为要计算偏移量,往往整个数组的地址就是第一个元素的地址,只有首位的索引是0才能计算得到自身
在集合中查找元素的复杂度层次:
O(n):遍历
O(logn):二分查找 / 搜索二叉树 / 平衡二叉树
O(1):在连续数组中根据偏移量计算出来,直接获取
HashMap也想实现这种不基于比较的查找,直接根据内容计算出来位置

添加过程:
计算哈希码:结果是一个int值
计算在哈希表中的存储位置:通过对数组的长度取模得到桶的索引
存入哈希表:
情况1:原本位置没有元素,一次添加成功
情况2:原本位置有元素,经过equals比较确认不是同一元素,则跟在这个桶后(链表后)
情况3:原本位置有元素,且原本桶内找到相同的元素,用新元素的value代替老元素的value
JDK 7 HashMap
底层就是一个数组+链表的存储结构
链表上每个节点是一个Entry,字段包括四部分

其中hash表示key的哈希码
默认的主数组长度为16
主数组的长度可以直接指定,但最终会变成大于指定数的2的幂
默认扩容因子是0.75(元素个数达到主数组长度的75%时扩容 - 重新创建新哈希表,将元素都重新装填进新的表中)控制数组存放数据的疏密程度;loadFactor越趋近于一,存放的数据越多,太多会导致查找元素效率低,太低又会导致利用率低、扩容频繁
每次主数组扩容为原来的2倍
当发生哈希冲突时,新元素需要和整个链表的节点进行比较(equals),如果确定不存在,考虑添加新节点:
JDK 1.7是在头部添加,1.8是在尾部添加
源码中关于put方法的执行:
如果key是null,则直接存入索引为0的桶中;
第一步:计算哈希码 – 其中除了获取hashCode外还要再多次变换hashcode
第二步:计算存储位置:使用位运算代替取余
第三步:判断key是否存在,判断策略是:比较一个桶内链表上entry的哈希码 –> key是否相同/是同一个对象

短路往往是为了提高效率,本身重写过equals的话可以直接调用equals,但理论上比key也有可能通过
扩容的条件是:节点数量达到阈值 && 新元素的位置已经有节点
尽量减少扩容次数,因为扩容会导致原来的节点要重新散列到新数组的位置
如果能够预估到节点可能散列到新列表的长度,就免去了取余位运算操作 – 1.8
为了减少扩容,需要预估节点的数量,在初始化时指定哈希表中主数组的长度
真正的扩容是由transfer()实现的,扩容需要重新创建一个新的哈希表(主数组),原来的entry都需要重新计算存储位置并添加到新的哈希表中;
第四步:如果发生冲突 / 取余后是同一个数,而且确定新数之前不存在,就将新元素包装成entry,添加到链表的最前面
细节问题:
为什么要把hash也放到Entry中
hash本身就是key的哈希值,避免使用时重复计算
- 扩容时需要用哈希来取余
- 判断key是否存在时需要直接比较哈希
为什么主数组的长度必须是2的幂次?
因为计算存储位置的公式 h&(length - 1);只有length是100000类型,length-1才能是111111类型,与运算才能达到取余的效果
为什么加载因子选择0.75?
默认负载因子在时间和空间成本之间提供了一个很好的权衡。较高的值( = 2)会减少复制次数,减少空间开销,但会导致链表过长,增加查找成本;较低的值(= 0.2)会导致扩容太频繁,空间开销过大;
JDK7 的死循环问题:
JDK1.7的新节点是添加到链表的头部,导致重新散列后,链表的节点顺序会颠倒;如果是单线程的情况下,这不算问题
但是在多线程环境下扩容时,多个线程同时执行transfer方法,可能扩容后形成循环列表

原本3指向7,第一个线程取出3后,原本要设置3的next = null,但在链表里一般通过某个指针来操作具体节点嘛,这个指针有可能在指向刚才断开连接操作前被覆盖,导致连接没有断开;
循环导致的问题:
- 如果下一步要get()一个不存在的key,或者put()一个不存在的key,都要先循环检查整个链表,检查的停止条件是next = null,所以导致根本停不下来
多线程put的时候为什么可能导致元素丢失
其实是多个线程可能都持有 new 的entry,但是添加到链表的过程中,是把上面指向头节点的指针指向new entry,再把new entry的指针指向原本头节点,如果两个线程都要往这个位置插入,就会导致之后上层只能找到最后一个线程添加的节点,之前的节点都只保留向下的引用,但却无法被访问到;
JDK 8 HashMap
- 结构变化: 由数组 + 链表 变成了数组 + 链表 + 红黑树

链表长度 >= 8,链表转化成红黑树;链表长度减少为6,红黑树退化成链表;但只有总的节点数量 >= 64时,才会有红黑树,否则直接进行主数组扩容
链表节点为node,红黑树节点为treeNode

添加到链表后面:JDK8后,新节点是加到最后,避免死循环(多线程下也不会导致节点顺序变化)
JDK8 的 put
细节问题:
为什么是当链表长度 >= 8 才变成红黑树?
首先哈希碰撞是个概率问题,这个概率问题符合泊松分布
也就是说对于很多的node要计算哈希投影到桶里,每个桶中链表的长度起始是符合泊松分布的
所以就可以算出来,链表长度为 n 时发生的概率大概为多少
在长度为8时,发生概率巨低,只有0.00000006,即转化成红黑树的概率很低
这个概率还受负载因子影响
计算哈希码的方法简单了

为什么要把高位也引入比较?
JDK1.7时期
1
2
3
4
5
6
7
8static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}因为取余操作:
n = table.length;
index = (n-1) & hash;n从16开始,翻倍扩容,即:只有低4 / 5 / 6 … 不为0,与操作会使hash的高位无效化
1.7的版本扰动能力更强,在n = 16时会把高于4位的很多部分都异或一遍
1.8的版本在性能和准确性中做了均衡
过程:

原来元素新的分布位置
主数组扩容位原来的二倍,匀速的索引要么是原来的索引,要么是原来的索引+原本数组容量
在JDK8中的transfer中,不进行存储位置的重新计算,而是判断此元素应该在原位置还是新位置
具体而言:就是要将原本挂在0位置的长链表,分成两个链表挂在两个节点上
hashMap维护了4个指针,分别是两个链表的头和尾,头是为了最后挂载到主数组上,尾是为了添加新节点
过程中遍历链表上每个node,添加到对应的链表尾巴上,最后再把头节点挂到主数组上。
单链表变成红黑树的过程:
简单来说,先把单链表变成双向链表,再将双向链表转化成红黑树。
1.8的hashMap虽然解决了扩容中的死循环和数据丢失,但仍然存在并发不安全的问题
只要存在【先判断、后操作】或者【先read、后write】,就有可能让某个线程在中间被挂起而数据被修改
复杂度分析:
查询的时间复杂度 = 遍历链表的次数
插入的时间复杂度 = 遍历链表的次数 + 扩容成本平均到每次插入的成本
遍历链表 O(k),取决于链表最大长度
扩容平均时间:在transfer不做优化时,扩容到N一共需要logN次,每次重新挂载所有节点需要O(N),于是所有扩容就需要O(N * logN),平均到每次插入logN
但是Java中transfer有优化
四指针移动
离线扩容(不占用用户线程的扩容)
ConcurrentHashMap!
JDK1.7中,架构和HashMap略有不同
HashMap既然是给整张map加锁,ConcurrentHashMap也顺应这个思路,只不过最外层包裹了多个HashMap(Segment),相当于将多个hashmap的主数组一字排开构成大hashmap,按照一段一段进行加锁;每个小hashmap通过引用绑定在segment上,所以扩容操作互不影响;
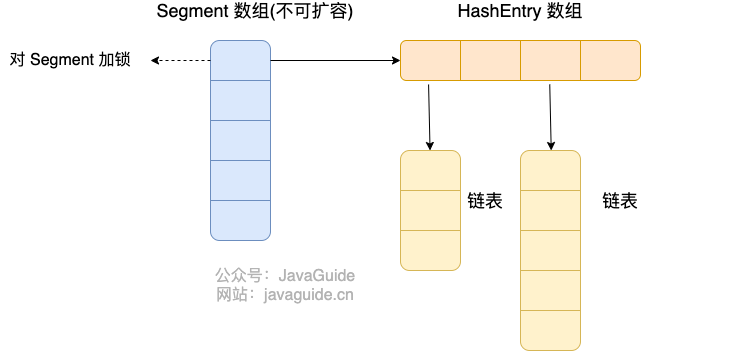
Segment默认长度为16,即:ConcurrentHashMap默认支持16个线程并发
HashMap喜欢通过位运算计算所有投影操作
计算哈希桶索引(put,get会根据key的hash投影找到桶,常规为了代码可读用 hash % length;而Hashmap
使用位运算代替取模
1
2
3
4
5
6
7final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
...
//n = tab.length
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
...当 length 为 2 的次幂时,
num & (length - 1) = num % length等式成立。hash扰动
见上
为什么选异或?
与 & 操作和或 | 操作的结果更偏向于 0 或者 1,而异或的结果 0 和 1 有均等的机会
哈希函数
哈希模型:
MD5 : 输出在 0 ~ 2e64 -1| String.length() = 16
SHa1: 输出在 0 ~ 2e128 -1 | String.length() = 32
Java的hashcode()会阉割一部分,只返回2e32 -1的范围,即长度为8
返回的内容是字符串表示的数,字符串每个char时 0到 f十六进制
哈希函数特征:
输入域无穷,输出域有限
相同的输入必然导致相同的输出 / 不存在随机的成分
不同输入有小概率产生相同输出 / 哈希碰撞
离散性 & 均匀性 | hash函数不依赖某个规律
离散性:相似的输入,产生离散的输出
均匀性:无论输入如何,结果都可以均匀分布在整个范围内
- 常用算法会将hashcode % m,同样能保证在0 ~ m-1上均匀分布
问题11:用过MySQL和Redis吗?
使用那种类型数据库取决于数据的性质
redis的应用场景:
缓存
计数器
分布式会话
排行榜
最新列表
分布式锁
消息队列
问题12:聊聊单例模式
单例模式,就是指在整个运行时域,一个类只有一个对象
为什么需要考虑单例模式呢?因为在整个项目运行中,有些类对象的创建成本是比较大的,如果频繁的创建和销毁对象会导致CPU性能消耗比较严重
例如:创建数据库连接的类对象只需要创建一次,后来的操作都复用即可
Java中如果实现单例模式:
多种写法,多种思维
方法1
1
2
3
4
5
6
7
8
9
10
11public class Singleton{
private Singleton(){};
//禁止在外创建,只能通过提供的API获取对象
private static Singleton instance = null;
public static Singleton getInstance(){
if(instance == null){
instance = new Singleton();
}
return instance;
}
}思想:【懒加载】 对象只有在第一次创建时才会被加载,这样做可以避免某个对象在程序中根本不会用到却创建了对象
问题在于:线程不安全
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15//使用双检锁加锁
public class Singleton{
private static volatile Singleton instance = null;
private Singleton(){};
public static Singleton getInstance(){
if(instance = null){
synchronized(Singleton.class){
if(instance == null){
instance = new Singleton();
}
}
}
return instance;
}
}
1 | |
用静态内部类
静态内部类只会在被引用到的时候被加载时加载一次,完美契合单例模式懒加载
注意:以上写法都可能被反射破坏——即通过反射创建出新的对象来
反射本身通过构造器newInstance创建的对象就不是单例的
要么人为避免,要么使用枚举类型【枚举类型不存在无参构造函数】
具体根据实例化时机分为饿汉式和懒汉式
饿汉:尽早实例化——在类加载的时期就实例化
1
2
3
4private static Singleton instance = new Singleton();
public static Singleton getInstance(){
return instance;
}懒汉:第一次调用时执行实例化
但第一次调用时如果是多线程场景下可能发生竞态问题
问题13:说说volatile
暂无
问题14:抓过包吗?
抓包是利用特定的软件对网络数据包进行拦截,通过对抓获数据包内的内容进行截获、重发、编辑、转存等操作
抓包对于软件的Debug有很大帮助,但更多应用场景在网络安全:比如了解攻击者所用方法,追查攻击者IP…
抓包的使用场景
检测web表单的隐藏字段:许多填写表单都有隐藏字段用来收集用户的数据、预防CRSF攻击、防爬虫等待…为了看到在界面上看不到的字段,只能使用抓包工具
想要进行压测,但单纯从Jmeter发请求可能达不到用户点击的效果,于是就需要用抓包的方式获取到用户访问接口的数据包,得知其中的协议内容、参数特点,为了更好的模拟用户请求
后端人的接口测试:观察接口的响应参数
利用抓的数据包检测数据加密情况
问题15:UDP怎么实现可靠传输?
改动UDP协议本身不可能,因为协议本身已经有很成熟的实现方案,试图在内部修改不太可能
只能从应用层面 / AOP代理一层中间层
现成产品:QUIC(Quick UDP Internet Connection) —- HTTP 3.0
为什么有了TCP,还需要UDP来确保稳定传输?
因为TCP无论上层想要传的数据是什么类型,都需要完成三次握手四次挥手来实现对所有数据类型的可靠传输;
【头阻塞】TCP为了保证数据包的有序,在传输过程中也要严格有序——一个包丢失需要等待直到这个包成功发送才能继续(为了可靠牺牲效率)
后来HTTP 2.0虽有多路复用,但没解决根本问题
QUIC:
基于UDP可以实现更多能够满足需求且成本比TCP低的方案【更灵活】
优点:
自定义连接机制
取消三次握手,在网络层只进行一次握手,可靠保证在应用层解决
解决头阻塞
自定义流量控制
改进的拥塞控制
问题16:synchronized和Lock锁的区别?
Synchronized
可重入锁,不可中断【阻塞队列中排队是不可中断的】,非公平的锁
每个对象的头部蕴含一把锁,每个对象都关联操作系统层面的一个监视器monitor(在mark word中存在指向monitor的指针);当一个线程想要进入代码块时,想要去看一下加锁对象的头部信息 - 即尝试获取锁,于是需要一个提供查看锁状态的API;当线程拿到锁进入代码块时,需要改变锁的状态,于是需要一个改变状态的API;此时别的线程想要执行代码块,只能阻塞直到锁释放,于是需要一个阻塞队列用来管理阻塞的线程,并且在锁释放时能唤醒阻塞队列,所有线程管理的操作都是围绕一个锁,一个对象的,所以就抽象出一个概念 - 锁的监视器 -- 监视器本身是操作系统层面的逻辑实现,负责管理线程。Synchronized底层通过对象Monitor实现,在进入 / 退出代码块 / 方法时会触发钩子【本质就是由monitor来改变对象头中的状态信息】,在字节码层面中体现为 monitorenter和monitorexit
monitorenter时表示尝试占用对象的锁资源,主要作用就是通过进入数来标识当前有无被占用,如果被占用了需要操作此线程让其阻塞,没有被占用则进入,进入数+1;
monitorexit:对于已经进入锁的线程而言,退出则把用于标识的进入数-1;
可重入锁:
指同一个线程可以多次获得同一个锁,而不会发生死锁
意味着线程在持有锁的情况下,可以再次请求并成功获取相同的锁,而不会被阻塞
实现方案:获取计数器
计数器维护的数就是当前线程递归加锁的层数,monitorexit一次再减一;
为什么要递归加锁?
防止死锁:方法上的synchronized都是用一个对象加锁,一不注意的调用就会导致递归加锁,如果synchronized是不可重入的那么就死锁
正常的代码应该不会写成递归加锁,因为外面的锁已经把其他线程阻塞住了里面的锁只会减慢性能;
所以使用场景就是避免死锁
不可中断锁:
当其余线程再等待的情况下,有没有一种方法能让阻塞的线程更加灵活,避免被阻塞就一直被阻塞
思路1:
不要轻易进入阻塞队列 – 通过探测锁有没有被获取来执行要不要获取
Lock对象的tryLock(),标识尝试获取锁,获取成功返回true,获取失败返回false
思路2:
线程进入阻塞队列,但可以尝试被中断
Lock中 lockInterruptibly()方法表示可被中断的加锁,中断方式就是Lock中 interrupt();
调用interrupt后,会在阻塞的位置【调用lockInterruptibly的位置】抛异常,所以捕获这个异常的位置就是让这个线程执行回调的地方;
Lock锁
Lock的使用场景是声明一个Lock对象,显式声明加锁给释放锁
特点:
可重入
互斥
可选是否公平
公平锁:等待时间较长的线程更容易获取锁
非公平锁:synchronized是阻塞的线程来争夺锁
可中断性
问题17:TCP/IP网络模型有哪几层:
应用层
传输层
网络层
网络接口层
每层所作的行为都是在下一层基础上功能的丰富,可以由网络的简单到复杂串联每一层的工作
最简单的网络 – 两个设备通过物理装置链接(物理层)
局域网(数据链路层,解决标识主机身份,共用线路…)
广域网(网络层,通过IP协议找到目标网络)
完成设备之间的通信,需要考虑应用之间的通信(传输层,基于TCP/UDP实现应用级别的数据传输)
用户接触的通信(应用层)
问题17:键入网址到网页响应,期间发生了什么
在浏览器中查找,第一步应该都是先排队。
即Timing中的Queueing:由于浏览器线程数有限,只能按照文件顺序依次查询

浏览器第一步:解析URL
解析出:协议 / 域名 / 文件名
解析之后,浏览器确认了web服务器和想要的文件名,根据此信息生成http请求【HTTP协议规定的报文】(开发者工具中看到的Request报文)
查询对应web服务器的IP地址 - DNS服务器
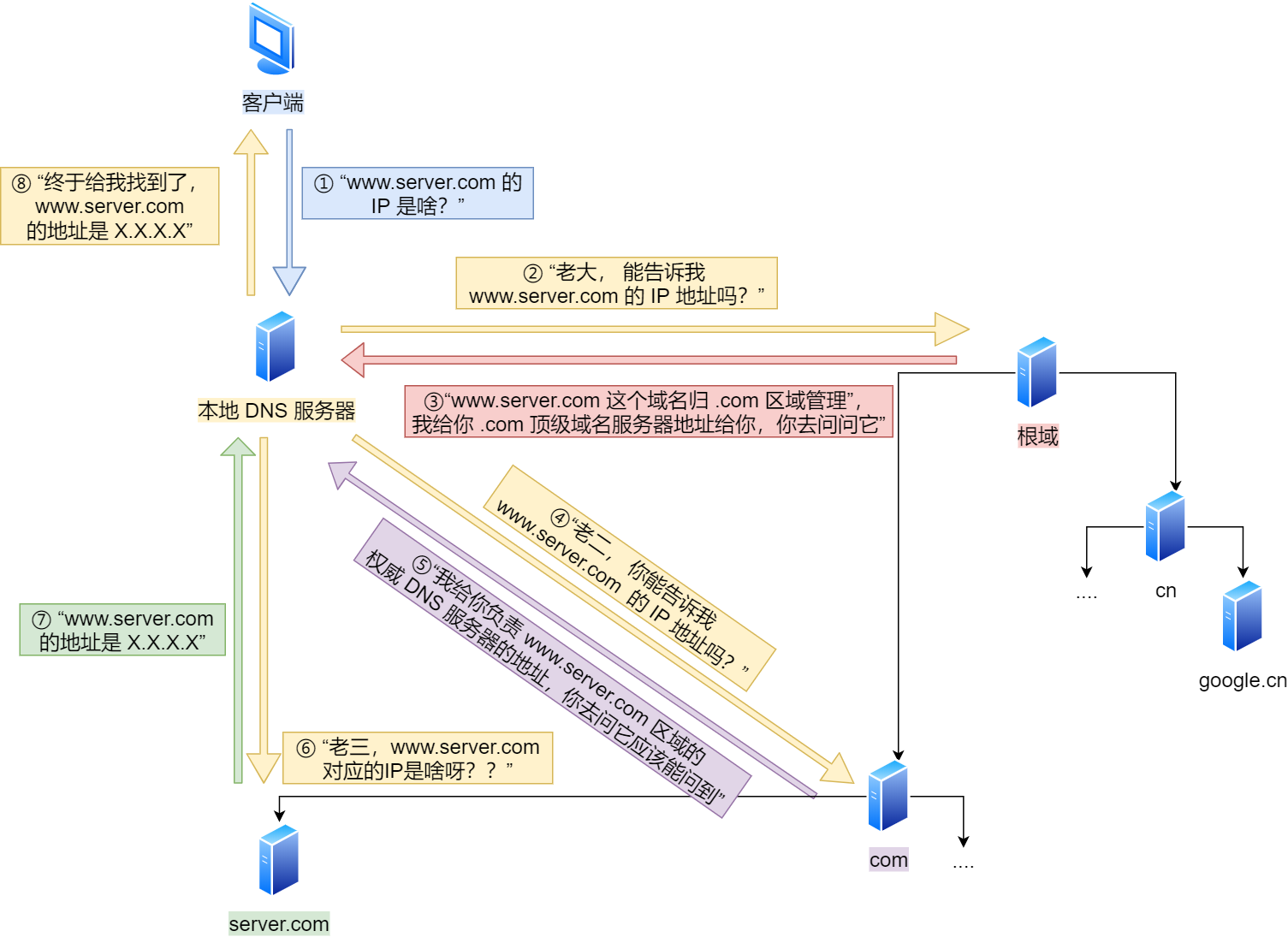
其中每个节点都有缓存,包括浏览器缓存IP,操作系统缓存IP,本地host文件可配置,再有各个DNS服务器的缓存
委托操作系统将消息发送给web服务器
电脑本身完成从应用层到链路层的一切工作,其中数据由应用程序通过socket交给操作系统就是由应用层到传输层的委托,同时也是用户态到内核态的切换
操作系统传输层和网络层维护TCP,UDP,IP协议栈;上层调用socket库就是间接调用协议栈工作
以TCP为例:
三次握手
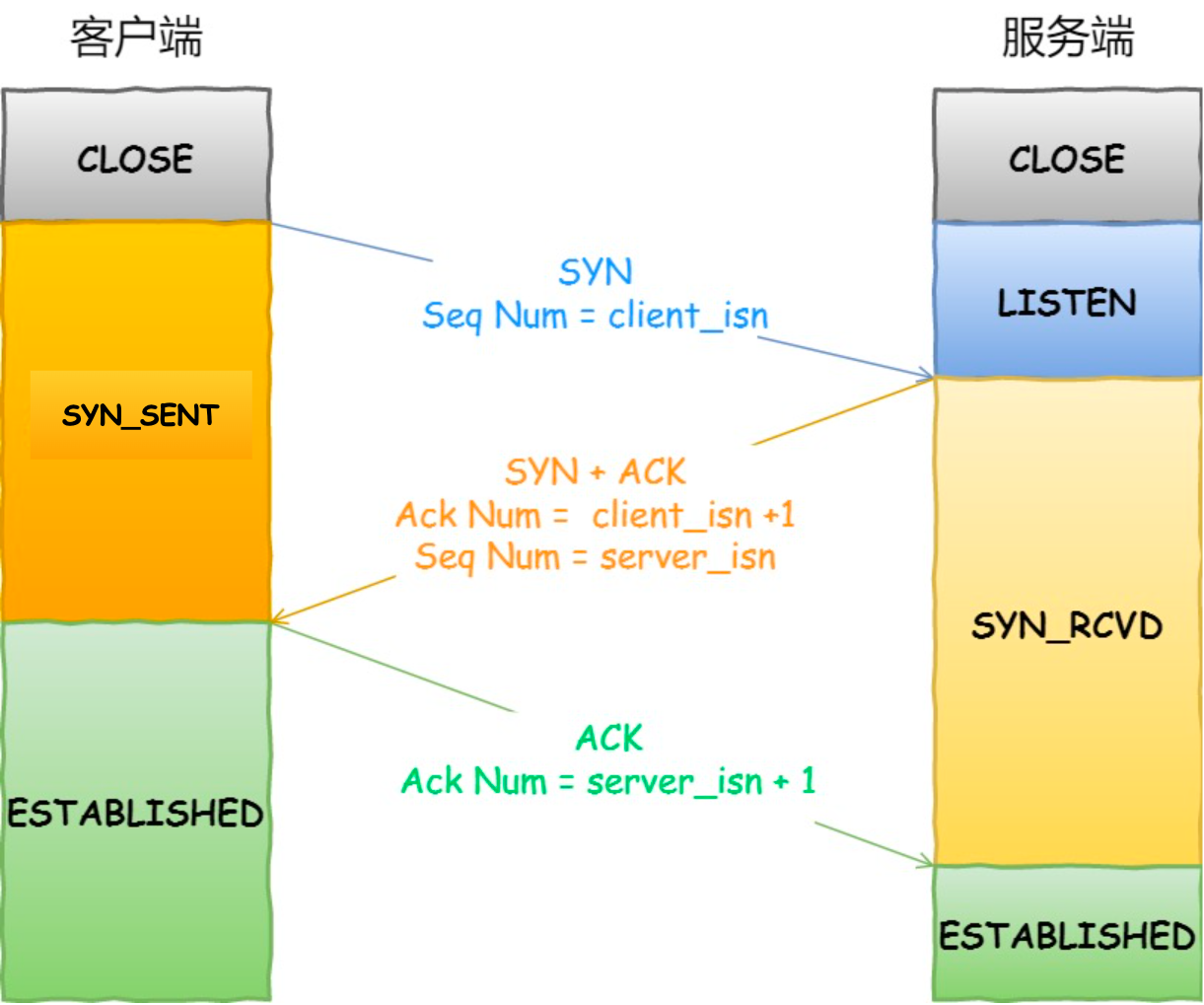
两端都要保证自身 能发,能收
过程:
最开始客户端和服务器都处于closed状态
服务器启动,监听某一端口,出于listen状态
客户端发起SYN(初始化序列号),之后处于SYN-SEND状态
服务器收到SYN,返回报文同时设置SYN + ACK,syn表示让对方也知道自己初始化的序列号,ack表示填入应答号(将对方上次的SYN序列号+1),之后处syn-rcvd状态
客户端收到syn-ack后,返回ack,之后处于established状态
服务器收到ack后,也处于established状态
风险:
类似拜占庭问题,任何一个单方向的请求其实都无法完全确认对方收到。
考虑为什么要有这一次握手,等价于考虑没有这次握手的风险
理论上有无数次握手都不够,但实际上,三次握手已经是可靠的工程解
因为在实际中,就算最后一下ACK没被成功接收,客户端也会发数据,服务器收到数据后自然跟新成established状态
并且还有超时重传机制,解决了就算客户端没数据可发,也不会干耗着
同时,三次握手其他能力:
同步序列号
序列号是每个TCP报文报头上携带的关键信息,作用有:
- 接收方可以去除重复的数据;
- 接收方可以根据数据包的序列号按序接收;
- 可以标识发送出去的数据包中, 哪些是已经被对方收到的(通过 ACK 报文中的序列号知道);
同步序列号的过程就是双方能够让对方接收到自身序列化,并返回一个序列号+1的应答
服务器方的序列号是什么?
TCP原生是双工,本来就可以由服务器向客户端发报文,就需要确认序列号
避免历史连接
总体而言就算为了防止旧的重复连接初始化造成混乱
在只有两次握手的场景下,服务器第一次握手后,就进入established状态,但是这样并不稳妥
场景1:历史连接
如果第一次握手握了两次,前次一由于网络问题阻塞了;所以会为两个请求都分别开启established,资源浪费
避免资源浪费
分割数据成数据包,每个数据包都会加上TCP头信息,生成TCP报文
通过头信息,可以参考本协议的功能 / 本层负责的任务
基本内容:
当前端口,目标端口
数据包的序号
应答号(在双方通信包中相互确认,用于包丢失)
指下一次「期望」收到的数据的序列号,发送端收到这个确认应答以后可以认为在这个序号以前的数据都已经被正常接收。状态位(SYN标识发起连接,ACK标识回复,RST表示重新连接,FIN表示结束链接),这是TCP和UDP不同的一点,TCP的包可以各司其职,而UDP面向无连接
窗口大小:负责流量控制(通信双方声明自己能处理的吞吐量)
拥塞控制:控制自己发送速度
交给IP协议栈发送
在IP协议中中生成IP报文
IP报文:
源地址IP,目标地址IP
为了能够被对方解析恢复成上层的样子,报头中就会携带上层类型参数:例如是TCP数据包,使用HTTP协议。
在数据链路层添加MAC头信息,生成MAC报文
mac头信息就是发送方和接收方的mac地址
即所用协议 IP / ARP
正式离开主机,从网卡转化成电信号
通过交换机离开局域网
通过路由器找到目标子网
在服务器层层扒皮,每层完成对应的校验工作
信息完整传递到服务器,客户端和服务器完成4次挥手
TCP协议是在传输层明确的通信方式,在底层还有更细节的工作
具体而言:
数据从主机出发,携带目标IP地址
线判断此IP是否在一个子网内(通过子网掩码的与运算),如果在,则查询交换机的IP-MAC对应表,直接发给对应主机;如果不在则交给路由器(默认网关)
路由器收到的IP数据包中有目标地址IP,根据路由算法算出下一个路由器
直接 / 间接到达目标主机所在子网和公网连接的路由器上
目标路由器查询自身以太网里交换机的IP-MAC对应表,将目标IP地址转化成目标MAC地址,发给主机
问题18:HTTP是什么
超文本传输协议
什么是超文本?
用文本表示,但超越不同文字的文本,最常见的HTML就是用xml表示图片、视频等内容,而HTTP在头部规定Content-Type,设置body的MIME类型;有text/html,application/json,iamge/jpeg,video/mp4…
常见状态码:

4XX
400 Bad Request :指客户端请求的报文有误,囊括很多错误,例如找不到方法,参数对不上,等等,比较笼统
403 Forbidden:服务器禁止访问某资源
404 Not Found:表示资源在改服务器上找不到
特殊header:
Connection:表示手否是长连接

upgrade:升级协议…
问题19:GET和POST是幂等的吗?
GET方法类似 只读,通常只是为了获取服务器上的资源。所以多次get的结果基本一致,并且据此浏览器可以设置get的缓存来加快访问。破除浏览器缓存 - 加一个随机数参数…
这只是RFC规范的定义,实际上GET也有做新增 / 删除的
POST方法通常表示 新增或者提交数据,会修改服务器上的资源,所以不是幂等的,浏览器一般也不会缓存
问题20:HTTP与HTTPS
区别:HTTP是明文传输,存在安全风险。HTTPS在TCP和HTTP层之间加入SSL/TLS安全协议,使得报文能够加密传输。
HTTP只需要三次握手后就能通信,而HTTPS在三次握手后还需要有SSL/TLS握手过程,确保能够建立安全的加密通道(过程中:协商加密算法,交换密钥…)
默认端口不一样:HTTP-80,HTTPS-443
问题21:HTTP/1.1 HTTP/2 HTTP/3的演变
HTTP/2对HTTP1.1的优化
全面二进制:
头信息和数据体都是二进制(按照实际意义编码),计算机收到后不需要再把明文转化成二进制,而是直接解析,增加了传输效率;同时更加节约空间
原本HTTP/1.1 在传输过程中,文本数据由ASCII这些字符集逐个字符编码,转化后的0101失去实际意义,只有解码后才能看到
并发传输 Stream
解决HTTP1.1的对头阻塞问题
只解决了HTTP层面的对头阻塞,但没解决TCP层面的对头阻塞
服务器推送
其中一种方案:webSocket
头部压缩(当多个请求头部相似,协议会消除重复部分 - 技术:在客户端和服务器同时维护一张头信息表,所有字段在表中由索引号存储)
HTTP3的优化
把HTTP下层的TCP协议改成UDP
通过QUIC协议实现可靠传输
问题22:对头阻塞
简单定义:当单个慢对象组织其他(后续)对象的前进
Head-of-line blocking
在HTTP1.1中,单条TCP连接上:在切换发送新资源之前,必须完整地传输完当前资源并得到响应:具体原因和纯文本传输有关,纯文本之间无法使用分隔符,导致不能将大文件切片后把小文件插入
所以一个浏览器页面会并行6个TCP连接,将请求分散,减少对头阻塞。
在HTTP2中,通过在每部分资源前添加”帧“,区分了每块所属。
HTTP2在每个块前添加数据帧,包括两个元数据:所属资源的流ID
以及块的大小
通过帧标识每个块的归属,允许在一个连接上正确复用多个资源
每个资源的传输抽象成Stream流,由Stream ID标识
HTTP2解决了应用层(HTTP)的对头阻塞,但没能解决TCP层的对头阻塞
TCP层的对头阻塞:
原因出在:TCP传输和HTTP2的传输是独立的。原本在HTTP2中将不同资源按照不同的流Stream传给TCP,TCP接收每个资源块后按流拼成相应的资源;其中如果一个资源块卡死了却不影响别的资源块进行传输;但是TCP传输也并非理想中的顺利
TCP也需要将资源分成多个块,每块顺次传输,但此时的分块和刚才HTTP的分块就没有关系了,此时的分块是随意的,并不是按照不同资源(js,css,html…)分的,这就导致TCP层面上,有些包由于网络问题没送到,其他后续的包只能等待它重发后才能一并交付给应用
总之,TCP 不知道 HTTP/2 的独立流(streams)这一事实意味着 TCP 层队头阻塞(由于丢失或延迟的数据包)也最终导致 HTTP 队头阻塞!
尝试解决TCP层的对头阻塞问题
要让TCP层知道某个包属于某个资源,而其他不属于统一资源的包可以直接交付给上层,而不用等
解决方案之一:QUIC
QUIC被看作是TCP 2.0,它包括TCP的所有特性(可靠性,拥塞控制,流量控制,排序)
QUIC将Stream ID的概念下移到传输层(原本在HTTP的应用层)
问题23:HTTP和RPC
二者都是基于TCP,原装的TCP是基于字节流的,也就是说单纯的通过0101二进制数据传输,收这些数据的一方由于不知道边界在哪所以很难处理成为有效数据
粘包
所以TCP纯裸状态下无法直接使用,需要规定更多规则 - 协议
比如说:在头部确认数据包的长度,编码集…
衍生出两类协议 HTTP 和 RPC
有HTTP,为什么还要RPC?
HTTP适合交互双方是异构的,共同遵守一套协议,而RPC可以实现的更加简单,定制化程序高(传输效率更高-因为http的header里无效数据还挺多),适合交互双方同构(CS架构)
使用的大致区别
- HTTP通过域名服务器找到目标地址,RPC往往工作在微服务模式下,通过注册中心找到目标地址
问题24:HTTP与WebSocket
场景痛点:
怎么样才能在用户不做任何操作的情况下,网页能收到消息并发生变更。
解决方案:
轮询
长轮询
以上两种方案适用于可以接收延迟的场景,比如扫码登陆…但是像打游戏就不行
webSocket
使用场景:
适用于 需要服务器和客户端频繁交互的场景
例如:小程序游戏,网页聊天室,飞书…
问题25:TCP机制
什么是TCP:
面向连接,一对一建立连接后才能进行通信
可靠,无论网络链路中出现怎样的变化,都能保证数据包到达对岸
基于字节流,二进制数据被操作系统分成多个TCP报文
确定一个TCP连接的要素
源地址
源端口
目标地址
目标端口
确定一个TCP报文则需要更多:
源端口
目标端口
序号:用于解决乱序问题
确认序号:目的是解决丢包问题
状态位:由于不同报文共用一个连接,所以有的报文在全局而言作用不同,总体而言是为了维护连接
SYN:发起连接
ACK:回复
RST:重新连接
FIN:结束连接
TCP如何实现可靠传输
明确解决的问题:
- 数据的破坏,丢包,重复,乱序…
机制:
- 序列号、确认应答、重发控制、连接管理、窗口控制等
问题26:TCP与UDP的区别
TCP提供复杂的控制机制,UDP协议则比较简单
头部格式如下:
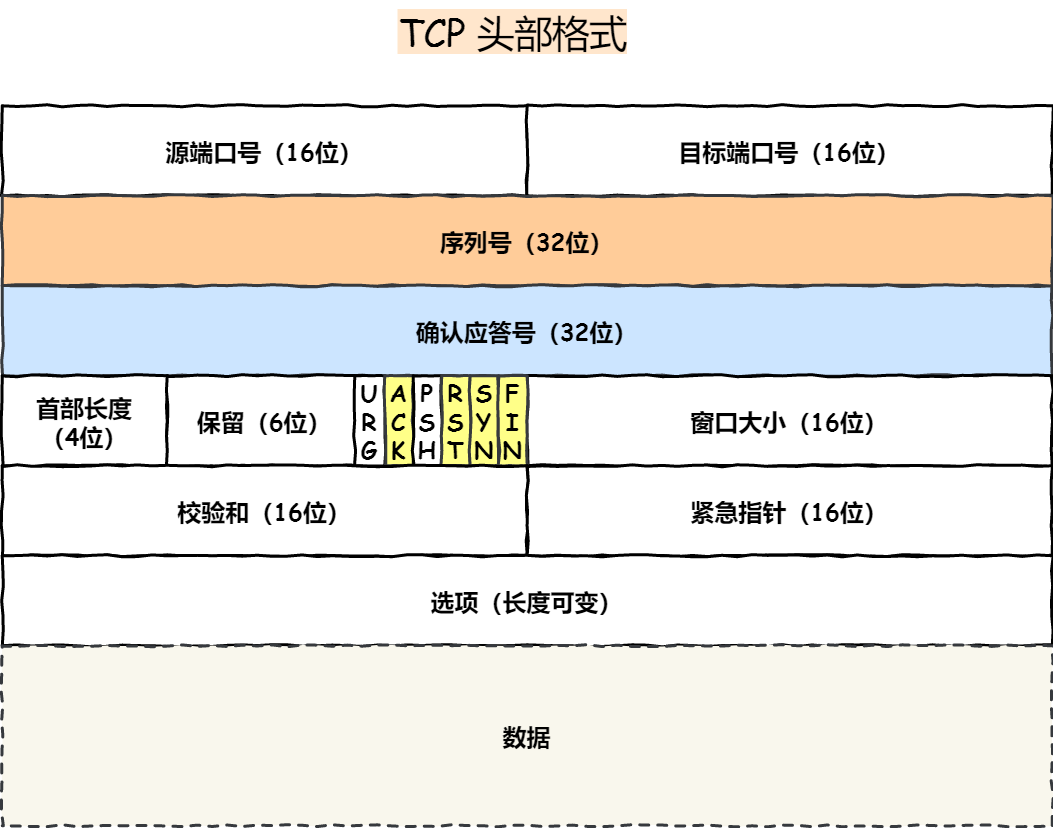
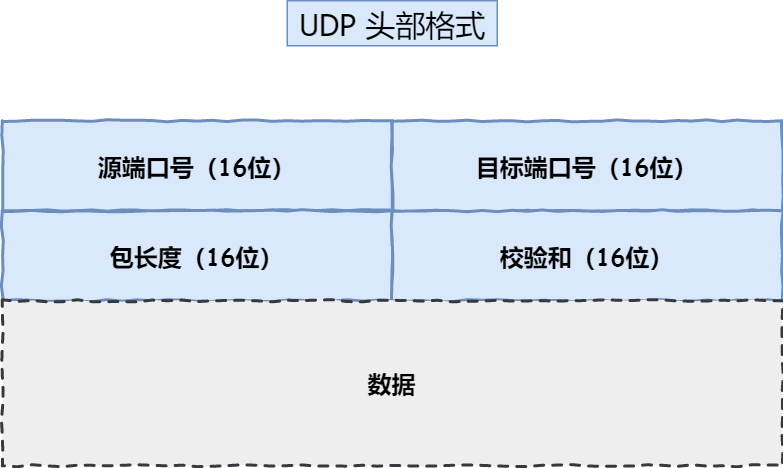
比较而言,TCP为了实现可靠传输多个几个标记:序列号用于排序,应答号用于防止丢包,控制位用来标识每个TCP数据包的作用,窗口大小用于控制流量…而UDP就只有双方地址,校验和,包长度这种必要信息
连接:TCP面向连接(传输前需要先建立连接),UDP无连接,随包发出即可传输数据
一对一,一对多:TCP一对一传输,一条连接上只有两个端点;UDP支持一对一,一对多,多对多的场景
一对多?聊天室?
UDP三种通信模式:
单播
广播:将消息分发到整个局域网内所有主机
组播(多播):将网络上的主机进行逻辑分组。将信息传递给一个小组内的设备
可靠性:TCP可靠交付,保证数据无差错、不丢失、不重复,不乱序;UDP无法保证但也尽力而为
拥塞控制,流量控制:
TCP之所以要有拥塞控制流量控制,是为了保证自己发的包别在网络中丢失,可能白发,可能再次同步需要时间;UDP不受负反馈调节的影响,网络拥堵也照样发
首部开销
使用场景:
TCP
由于可靠性交付
HTTP/HTTPS
FTP文件传输
SMTP电子邮件
TELNET远程终端接入
UDP (由于协议本身不可靠,尝试可靠的操作只能由上层应用程序来做)
高效
音视频,多媒体
广播,聊天室
问题27:如何基于UDP协议实现可靠重传?
思路,按照TCP的保证方案,在UDP中做到类似效果
- 不改变UDP的具体形式(报头),只能在上层完成功能强化【在UDP的保温内部再分出细节】
TCP的缺陷:
TCP建立连接过程有延迟
TCP存在对头阻塞问题
网络迁移需要重新建立TCP连接
市面上基于UDP实现的可靠传输方案:QUIC(HTTP/3)
QUIC:
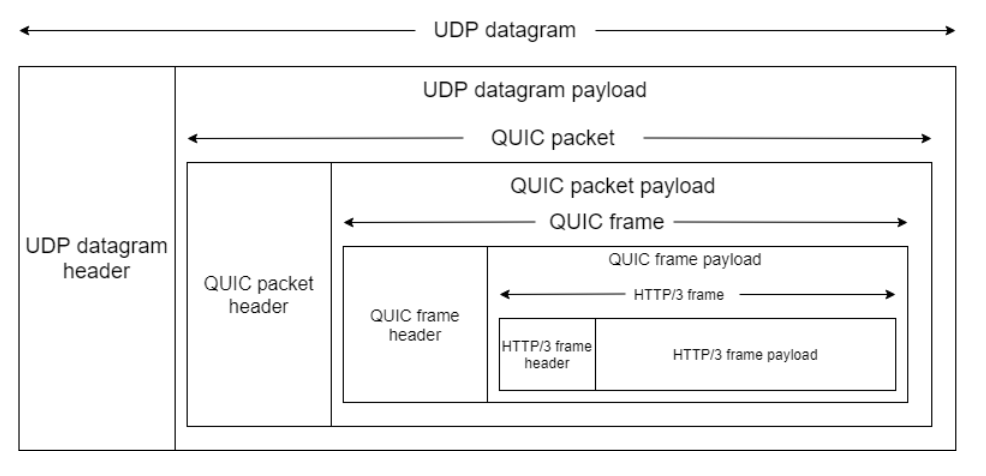
在传统HTTP报文上,添加了许多QUIC报头,最后再用UDP报头封装所以
points:
解决对头阻塞问题:
传统TCP需要按照序列号顺序确认,一个包由于网络时延导致其他包无法确认
QUIC将确认的序列号和排序的序列号分开 - 于是可以乱序确认;
排序的序列号Stream ID
问题28:Java前沿技术
ZGC & Shenandoah
回来吧我的ZGC
设计目标:适用于大内存、低延迟的服务
传统G1由于在复制阶段需要STW导致响应时延较长,ZGC尝试在全部阶段几乎都并发执行;
最后目标是:RT < 10ms
原理:将传统整个转移赋值STW的阶段分成初始转移+并发转移
【核心在于能把STW的过程分出必要的STW和基于结果可以并发执行的阶段】,G1无法分离,因为转移过程中对象地址无法准确定位。
关键技术:
由于在对象复制阶段想要并发执行,用户线程就要准确定位到目标对象的位置(即使对象发生转移)
方案比Shenandoah更加复杂精妙
读屏障:把线程获取到的不对的指针更新到对的地址上
着色指针:用来判断对象是否移动
读屏障
读屏障 Load Barrier:在读的指令前后,插入某个指令来实现具体需求【AOP】
传统G1面临的问题是:当对象转移时,如果线程尝试写对象可能写在旧的位置,ZGC需要解决任何写操作的目标都确保都是新对象读屏障就是要插入这样一段代码
在读到对象时,先判断当前对象是不是新的,如果不是新的则将引用重定向到新的位置
技术难点:
如何判断是新是旧?
在着色指针内的四个bit位标识当前对象的状态
新的位置在哪?
维护公共的转移映射表,由此表从旧对象找到新对象
着色指针:
由于原本84位计算机上表示内存地址的8字节有点大,Windows操作系统也只用了44位
ZGC将中间4位表示四种状态,由此在不占用额外空间的状态下表明这个指针指向的对象的状态
动态Region:大小由2MB,32MB以及更大
JDK21之后,ZGC设计了分代回收机制
时延短,代价是吞吐量下降【没有纯粹使用线程来垃圾回收,而是并发的使用少量线程做回收,势必吞吐量不足】
回来吧我的Shenandoah
不太追求时延,不要求pause < 10ms;换来吞吐量
比G1优化的点:
并发的整理算法
默认不使用分代收集
摒弃G1中的记忆集,而用一个全局的数据结构-连接矩阵-来记录跨Region引用关系
解决并发回收时对象位置的技术
Brooks Pointer【转发指针】
在每个对象头部维护重定向信息
复杂性要求更高——用户线程如果要修改对象,只能在新地址修改,即要求垃圾回收线程提前把对象复制好并且更新转发地址
阻塞用户线程
CAS自旋尝试 / 等待复制完成
读屏障 –> 引用访问屏障
读屏障:相当于读取对象操作的AOP,用于在具体读的指令之前将对对象的指针指向正确位置(具体操作就是看转发指针是否指向自身,指向其他位置则表示新对象在其他地方,要在接下来的访问目标前准确替换成新对象 —— 读前屏障)
GraalVM
一款高性能JDK,官方标语:Build faster,smaller,leaner applications
特点:
更低的CPU、内存使用率

早期使用JIT预热阶段CPU消耗较高,包括没有热点代码加速的消耗和编译热点代码的消耗
更快的启动速度
GraalVM在启动 + 处理第一个请求的时延更快
通过Truffle框架运行JS,Python,Ruby等语言
模块化
Java 9开始,引入模块系统,Java开始微服务化


传统jar包下就是编译后的.class文件,模块化后——模块就是在jar之上再抽象一层,用来管理原先复杂的依赖网
模块 = jar + module-info.class
其中包含:
- 模块名称
- 依赖哪些模块
- 导出模块内的哪些包(允许直接
import使用) - 开放模块内的哪些包(允许通过 Java 反射访问)
- 提供哪些服务
- 依赖哪些服务
看似好像什么也没改,实则有四点好处
为依赖管理而制定的规则:
只要module-info.class表示正确,就可以通过此描述文件计算依赖关系,一旦发现循环依赖,启动就可以报错了
早期解决方案如果没有maven的话,可能需要在编译期间沿着jar包进行DFS才能发现循环
maven有pom.xml,相当于对管理的jar包的索引,通过此建立分析的依赖树
精简JRE:
模块化后JDK被分成94个模块,通过jlink随意组合生成自定义的KRE可以缩小JRE大小
通过 –add-modules可以将依赖的模块添加到运行时镜像中
更精准的权限管理

public粒度太大,如果只想实现对部分modules是public就无力了
将访问权限管理细分,更有助于实现封装逻辑
模块化后,各个模块独立开发,效率较高
Java为module-info.java设计了专门的语法
open / export / requires …
java var
从Java10开始,可以从变量的初始值推导变量的类型,于是呈现出Java可以为弱类型语言
问题29:包装类型的缓存机制
Java基本数据类型的包装类型都用到缓存机制来提升性能
Integer:-128到127
当基本数据类型想要包装时,会优先检查在不在缓存范围内,不在则执行new操作
缓存的范围区间是在性能和资源之间的权衡
问题30:如何解决精度丢失问题 & 超过long类型的数据
使用BigDecimal实现对浮点数的运算
使用BigInteger实现对超过64为整型的表示
问题31:浅拷贝 & 深拷贝
浅拷贝:只拷贝最外层,内层还是同一个数据
传统clone()就只会创建一个和this对等的对象,而this内其他引用任然保留
实现Cloneable后重写clone可以手动实现深拷贝
深拷贝:深浅全部是新的
问题32:String不可变:
技术上如何实现不可变:
String本体是char数组 / byte数组,这个数组被final修饰导致引用不可变
整个String类没有提供public的修改数组内容的方法,所以数组无法直接由String对象改变
String类本体被final修饰,无法有子类继承数组,也就不会有新方法来修改
为什么这么设计?
场景1:由String做HashMap的key时,需求保证不可变才能维护哈希表正常运转
场景2:由于字符串常量池
字符串在人眼里的含义更多是其字面量,某些字符串就应该不变,而不是具有变量的属性
常量池内维护许多String对象,每个对象都被许多地方引用;如何一个线程改变了变量的值,其他引用的地方也会悄悄变化
问题33:说说集合框架
主要有两大接口派生而来
Collection:用来存放单一元素
有三个子接口:List,Set,Queue
Colloction接口定义了单个元素容器的普遍规范,也就是在List,Set,Queue中都应该具有的API

List:
特殊的API有:排序,静态of方法用于构建List…
实现类:
ArrayList:用Object[]维护
Vector:Object[]
LinkedList:双向链表
Set:
特殊API:of,构造函数
实现类:
HashSet:底层采用HashMap
LinkedHashSet:底层采用LinkedHashMap
TreeSet:底层采用红黑树
Queue:
特殊API:offer,poll,peek…
实现类:
默认实现类是LinkedList,LinkedList实现Deque接口(双向链表 天生适合 双端队列)
PriorityQueue:小根堆实现优先队列
DelayQueue:延迟队列
ArrayDeque:可扩容动态双端队列
BlockingQueue:阻塞队列
实现类:
考虑的点:
Queue长度是否有限
生产者和消费者共享一把锁 / 锁分离
ArrayBlockingQueue:使用数组实现的有界阻塞队列
实现方案:
内部维护定长的数组
通过使用ReentrantLock对都系欸对象进行同步
通过Condition实现线程间的等待和唤醒操作
维护两个Condition对象,分别用来阻塞 & 唤醒 两组线程
- 队列满时,生产者线程等待,一旦被消费者消费一个则通过此Condition唤醒一个生产者
LinkedBlockingQueue:使用单向链表实现的阻塞队列
PriorityBlockingQueue:支持优先级排序的阻塞队列,需要元素实现Comparable或者Queue传入Comparator
SynchronousQueue:同步队列
DelayQueue:延迟队列
Map:用来存放键值对
实现类:
HashMap:
LinkedHashMap:继承自HashMap,底层仍然维护数组+链表,此外还有一条双线链表维护节点的插入顺序
Hashtable:
TreeMap:底层采用红黑树
问题34:Spring
IOC:
控制反转:原本对对象创建和管理的控制由开发者交给框架
IOC容器类似一个工厂,当需要创建一个对象时,只需要根据配置文件 / 注解 按需获取即可注入,而不需要考虑如何创建出来
IOC容器负责全局对象的管理,当我们注入一个service时,service内部依赖的各种对象全都由容器按需注入;假如没有容器自动管理,则service的构造函数中还要传入各种内部变量的具体值,dao / mapper…
如果写死的话意味着耦合性很高,当想要替换某一个dao下不同daoImpl时需要改源代码,而不写死,开发者只需要将具体Impl交给IoC,即可完成注入
本质:由写死在代码的配置关系移动到配置文件 / 编码阶段的注解中
由于注解还是和代码耦合在一起的,虽然更简单,使用配置文件解耦程度更高
IoC容器实际上就是一个Map,也是一个bean Factory
Bean factory:是所有Bean容器的根接口,定义了容器的基本方法
IoC生命周期:
- 创建容器
1
ApplicationContext context = new ClassPathXmlApplicationContext(...)AllicationContext类就表示IoC容器,不同的实现类为了兼容不同的场景,由xml的,注解的..
解析配置文件,操作Bean对象
操作过程【Refresh方法】
解析配置文件Bean定义,将beanDefinition注册到BeanFactory中
钩子:PostProcessor:指在所有Bean注册完成后,初始化前后可以进行些认为操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17import org.springframework.beans.BeansException;
import org.springframework.beans.factory.config.BeanPostProcessor;
public class MyBeanPostProcessor implements BeanPostProcessor {
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) throws BeansException {
System.out.println("Before Initialization: " + beanName);
return bean;
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) throws BeansException {
System.out.println("After Initialization: " + beanName);
return bean;
}
}初始化所有singleton bean(lazy-init的除外)
初始化过程中,也有钩子允许加载
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40import org.springframework.beans.factory.*;
public class MyBean implements BeanNameAware, BeanClassLoaderAware, BeanFactoryAware, InitializingBean {
private String beanName;
private ClassLoader classLoader;
private BeanFactory beanFactory;
// 实现 BeanNameAware 接口的方法
@Override
public void setBeanName(String name) {
this.beanName = name;
System.out.println("Bean Name: " + name);
}
// 实现 BeanClassLoaderAware 接口的方法
@Override
public void setBeanClassLoader(ClassLoader classLoader) {
this.classLoader = classLoader;
System.out.println("Bean ClassLoader: " + classLoader);
}
// 实现 BeanFactoryAware 接口的方法
@Override
public void setBeanFactory(BeanFactory beanFactory) throws BeansException {
this.beanFactory = beanFactory;
System.out.println("Bean Factory: " + beanFactory);
}
// 实现 InitializingBean 接口的方法
@Override
public void afterPropertiesSet() throws Exception {
System.out.println("InitializingBean's afterPropertiesSet() method");
}
// 自定义的初始化方法,对应配置文件中的 init-method 属性
public void customInitMethod() {
System.out.println("Custom Init Method specified in configuration file");
}
}广播事件:表示Context加载完成
管理bean对象
1
MessageService messageService = context.getBean(MessageService.class);Bean
Bean的作用域:
Singleton:IoC容器中使用单例的bean
prototype:每次获取都会创建一个新的bean示例
request:每一次HTTP请求都会创建一个新bean
session
webSocket:每一次webSocket会话产生一个新bean
Bean是线程安全的吗
prototype作用域下是的,不存在资源竞争问题
singleton下未必,如果此对象类似只读(只负责提供方法:如serviceImpl)就是线程安全的,但如果有会被修改的成员变量就需要小心
运行弱一致性:可以将可变的成员变量定义成ThreadLocal中的内容
强一致性:加锁
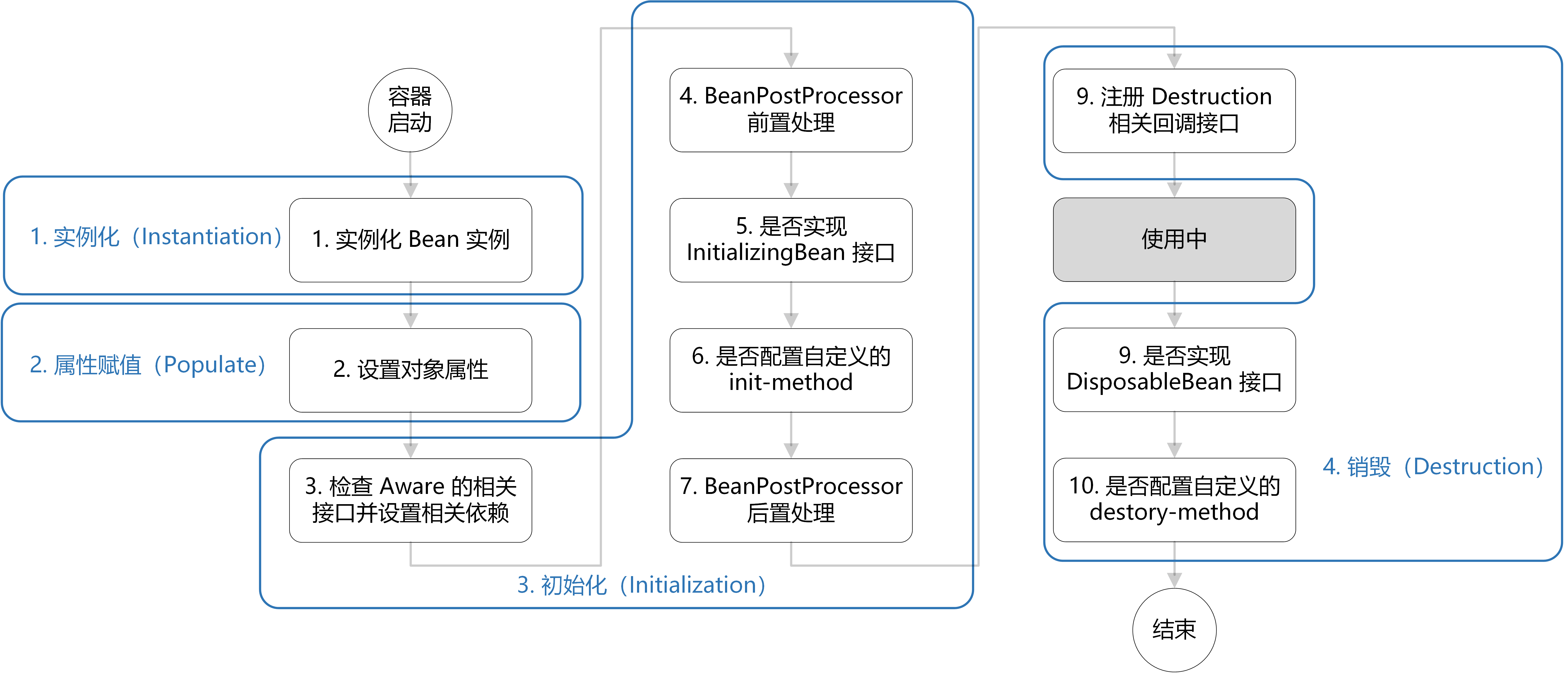
Bean的生命周期:
处处定义钩子
创建bean实例,在xml中找到后通过反射创建
属性赋值 / 依赖注入
bean初始化 执行Aware接口实现类
销毁bean,执行destroy实现方法的代码
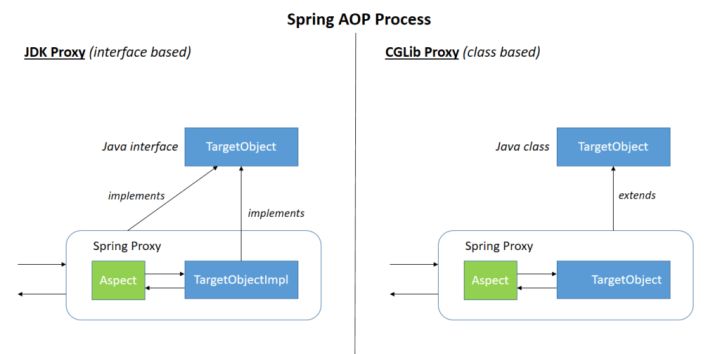
AOP
Aspect-Oriented Programming
将于业务无关的、却为业务模块共同服务的逻辑封装起来,减少代码重复,降低耦合,提高可读…
事务管理、日志系统、权限校验…
实现方式:动态代理【当被代理的对象实现了某个接口 / 要AOP的方法都是override的,Spring会使用JDK Proxy,没有接口的对象使用Cglib】
基于AOP思想的又一实现:AspectJ
一个AOP框架,方便实现在切入点上运行切面代码
区别:传统AOP基于动态代理,AspectJ基于字节码增强——将目标代码的引用(invokeVirtual)直接插入.class文件具体位置
问题35:Java注解如何实现的 //TODO
注解是什么:有点像注释,只不过是给机器看的注释,当机器注意到此注解时要执行响应逻辑
注解分为
运行时可见的注解
运行时不可见的注解
注解本质是一个接口,在class文件中标明是interface
在一个添加了注解的class文件中,如果方法上加了注解,方法后会有一个属性RuntimeVisibleAnnotations,类上如果有注解则class文件最后会有RuntimeVisibleAnnotations
JAF
Gobrs-Async
Gobrs-Async是一款功能强大、配置灵活、带有全链路异常回调、内存优化、异常状态管理于一身的高性能多线程并发编程和动态编排框架。
1 | |
沟帮烧鸡的执行流程:
功能:
通过配置文件编排好任务的执行顺序,并且可以很复杂(很切合实际场景),例如:当ABC中任何一个任务执行完立即执行任务D,且停止ABC的执行,明显就是登录场景
而任务的声明也只需要在原先代码的基础上声明注解Tesk即可,还可添加参数,设置超时时间,重试次数等等…
和常规CompeletableFeature的区别:
更加灵活:
- 原本使用Feature类开发时,任务都是按Runnable类型的lambda表达式写的,所有任务链路写在一起,通过thenRun等表达式串联
- 使用沟帮烧鸡后,每个任务有自身钩子函数(prepare:任务开始前执行什么操作,onsuccess:任务成功后执行什么操作,nessary,什么条件下执行此操作…)
技术:
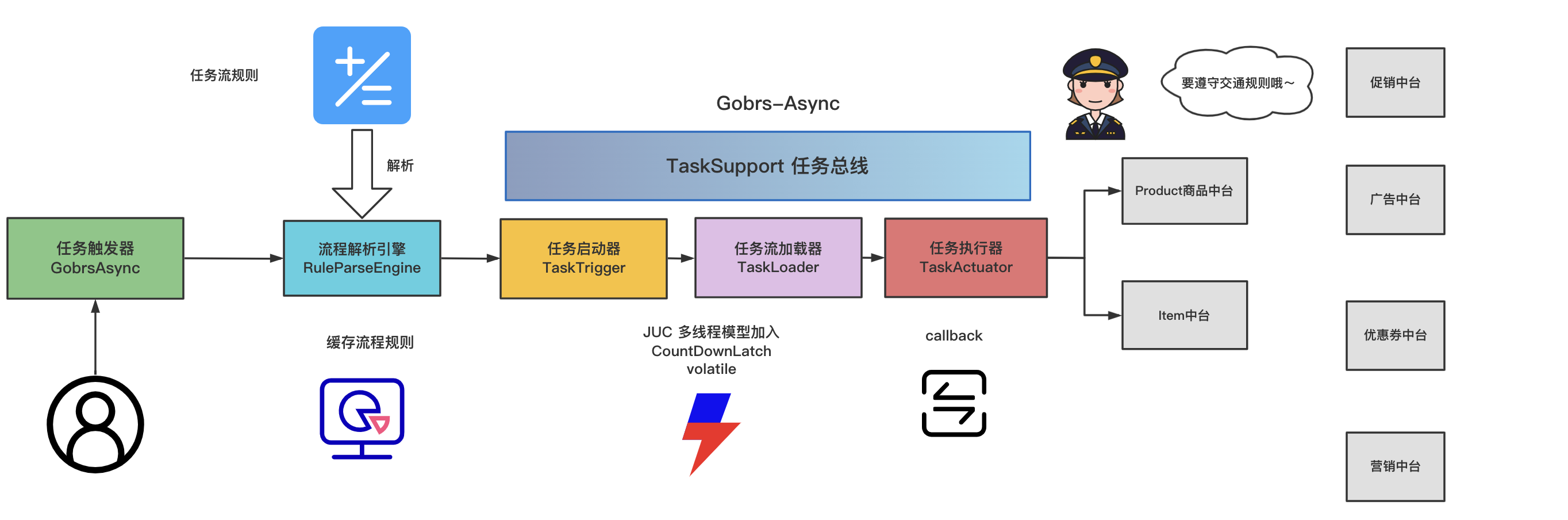
角色:
任务触发器:面向调用者,负责启动任务执行流
规则解析引擎:负责解析配置文件,将配置信息加载成bean对象,再组装成任务树
任务启动器:启动执行任务树上的方法
任务加载器:负责调用任务执行器
任务执行器:…
how to do this
主要使用
CountDownLatch、ReentrantLock、volatile等一系列并发技术开发设计。
DynamicTp
使用ThreadPoolExecutor的痛点
代码中创建了一个ThreadPoolExecutor,但是不知道那几个核心参数设置多少比较合适
凭经验设置参数值,上线后发现需要调整,改代码重启服务,非常麻烦
线程池相对开发人员来说是个黑盒,运行情况不能感知到,直到出现问题
原生ThreadPoolExecutor其实提供了set参数的方法,允许在运行时动态设置参数值
但是触发set方法怎么能够更加灵活——即使是运维人员也可以简单修改——又结合配置中心的思想(微服务体系中将配置信息解耦),最后总结出:结合配置中心来做运行时线程池参数的动态调整
主要功能模块:
配置变更监听模块
监听特定配置中心的指定配置文件
解析配置文件内容
通知线程池管理模块实现刷新
线程池管理模块
启动时从配置中心拉取配置信息,生成线程池实例,注册到内部线程池注册中心中
不仅可以使自身DtpExector创建时按照配置中的信息,也可以控制web服务器的线程池 —— 通过adaptor模块
监听模块监听到配置变更时,将变更信息传递给管理模块,实现参数刷新
维护对线程池的crud
监控模块
通知告警模块
告警类型
线程池参数变更
阻塞队列容量达到阈值
线程池活性达到阈值
触发拒绝策略
adaptor模块的设计思路
想要管理第三方组件的线程池,首先要明确在这些组件中线程池是如何使用的,也就是整个请求的链路中,线程池的行为如何;
如果其关键作用的线程池提供了public的set方法供二次开发者调用,那最好,否则需要通过反射来拿
Tomcat中的线程池
Tomcat对于原生线程池做了一定优化,主要在什么时候创建新线程方面调整了策略
原生线程池使用场景是CPU密集型:因为原生线程池中,核心线程数就是CPU核数,再多对于CPU而言就没太大压榨空间了,反而多了切换的成本
Tomcat线程池使用场景是IO密集型,为了吞吐量增大点切换成本是合理的,所以此线程池并不可以维护核心线程数,而是能增就增,直到最大线程数
同时,提供了获取线程池的public方法,可以用来封装修改参数的逻辑
Tomcat内部架构:

最外层是一个web Server
内部将请求监听和请求处理解耦运行,Connector连接器负责开启socket并监听客户端请求,返回响应数据,Engine模块负责具体的请求处理
将一个Engine模块和多个连接器组合,成为一个Service模块
在Engine内要运行一个web应用
区分Host【一台Tomcat可以按不同域名来分别执行逻辑】
Host下的Context模块就表示一个web应用的环境
Context内包含多个Servlet
连接器的功能:
基本逻辑:
网络请求到达EndPoint,以TCP/IP报文的形式
在EndPoint处理成Socket信息,给到Processor
在Processor中转化成HTTP信息
提取出Tomcat Request后,给到Adaptor
Adaptor交给容器Servlet Request

Tomcat源码
ThreadPoolExector找不到的原因是:
上层使用的都是接口类型
创建多态对象时使用的是工厂设计模式(newInstance而不是new ThreadPoolExecutor)
底层封装有API,不直接解除Executor
ThreadPoolExector具体使用
在NIO中,只作为read和write成功后的回调
在BIO中,作为任务异步执行的真身
leaf
分布式全局唯一ID生成工具
问题场景:
分库分表后需要有唯一ID,但使用传统的自增id不行
分布式场景下多台服务器需要对唯一ID有共识
传统方式:
直接通过DB自增方式生成ID
使用redis缓存生成ID
直接使用UUID生成ID
雪花snowflake
问题:
UUID:长度过长(128bit),完全随机(无序)
尤其当作为数据库主键时,占用空间太大。
UUID会保留MAC地址信息
加入新数据时并非一条条往后,而是完全随机(没有自增的趋势),中间裂页复制的成本很高
【并且最无语的时,大概率目标页还在磁盘中,还要有一次IO - 约等于要维护整个B+树在内存】
Redis自增
由于redis支持原子性操作使得一个数自增
- redis是一个内存数据库,需要考虑持久化和重启后续上、以及高可用的问题
传统自增ID不仅分库分表解决不了,还有些业务问题
容易暴露信息,让人猜到订单数
无法区分不同业务(应该让不同业务的id也有所不同,出问题好定位)
雪花:
一种以划分命名空间来生成不同ID的算法——将64bit位划成多端,分别表示机器,时间…
优点:
能够做到自增趋势:因为时间戳在高位,自增序列在低维。时间戳基本自增,即使一样也有自增序列兜底
根据自身业务设计bit位
缺点:
- 强依赖机器时钟,如果机器时钟回拨会导致ID紊乱
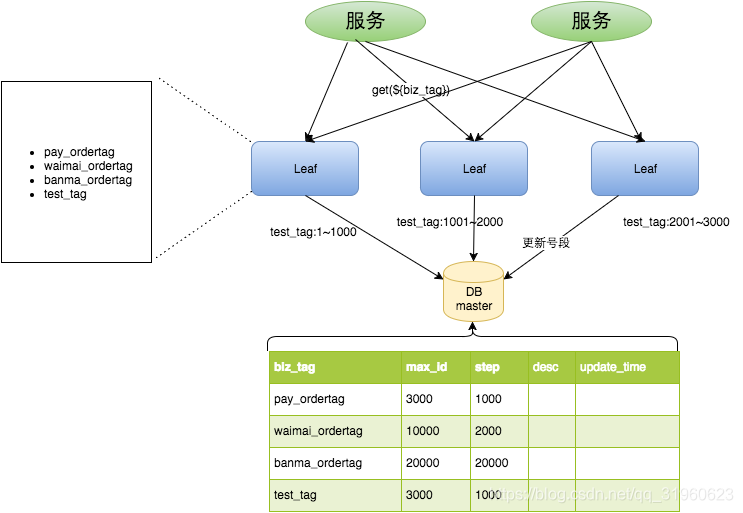
leaf的方案:
Leaf-segment【预分发号段】
在使用原本数据库的方案上,为了避免每获取一次ID就读写一次数据库,提出按照segment获取的方案
即:每次拿走多个ID,用完在来读写数据库重新获取
虽然是基于数据库,但是即使数据库分库分表,将不同segment分配给不同单位即可
优点:
在线扩容很方便
leaf单独作为一个服务,和DB耦合程度不太高,即使DB宕机,leaf仍然能坚持到自身号段用完
缺点:
ID号码不够随机
还是对DB有耦合,一旦宕机会不可以
对数据库的更新操作还是会阻塞一部分获取ID的请求
优化缺点3:双Buffer【一个server基本会拥有两个段号,轮流对外提供服务】
即:在消费完之前某一时刻间下一块segment请求回来
解决3,部分缓解2
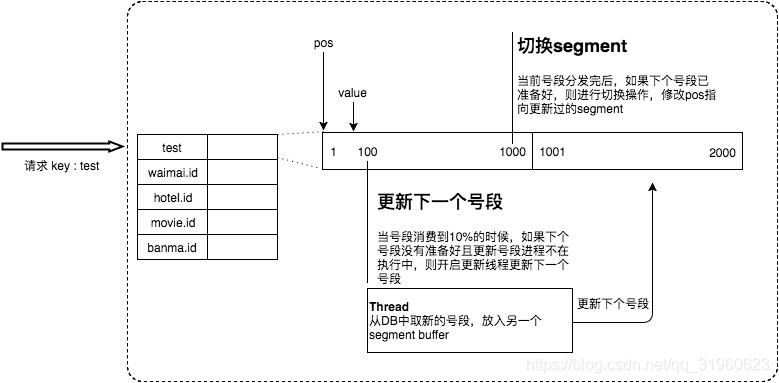
动态步长策略
上一次更新周期长,说明使用id频率不高,这次分配数量也不多
上一次更新周期短,很可能表示流量很大,则一次性分配更多ID
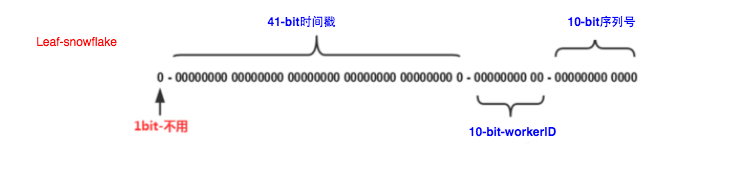
Leaf-snowflack
原本的segment方案生成的ID呈递增趋势,但是比较连续,可以被对手计算得到可用信息
于是引用雪花算法
leaf-snowflake沿用雪花算法的bit位设计方案
解决时钟问题:
重启后校验一下之前的记录和当前时间
如果当前时间在之前记录之前,说明时钟回拨过大
雪花算法
jetCache
高并发三剑客
缓存、分库分表、消息队列
在技术领域,没有一种通用方案可以解决所有问题 —— 没有银弹
缓存:
空间换时间,减少对CPU的消耗和IO成本
缓存分类
本地缓存
JDK map 在内存中维护一个get的时间复杂度为常数的数据结构
本地缓存框架:Spring Cache、Guava Cache
池化思想本身也是缓存思想(空间换时间)
问题:集群模式下无法共享
重启服务缓存消失,突然的雪崩
分布式缓存
指:和应用分离的缓存组件 / 服务
与本地应用隔离,多个应用直接共享缓存
常用技术:Redis、Memcache、tair
JDK中的map
HashMap & ConcurrentHashMap
LinkedHashMap:有序的Hashmap,保留元素的插入顺序
常用来实现LRU链表
TreeMap:基于红黑树的有序Map,可以按照键的顺序进行遍历
本地缓存应用框架
由于要对缓存内容进行管理,例如过期失效,淘汰策略…
分布式缓存
分布式缓存通常由多台机器组成一个集群,目的是将缓存数据分布在多台机器上·,以提高缓存容量和并发能力
优点:
性能可扩展
高可用(集群,主备)
缺点:
- 网络延迟
多级缓存
本地 + 分布式
既能加快访问(进程内就有本地缓存)
还能减少风险(分布式服务也有)

细说JDK中四种用于缓存的数据结构
HashMap
Rabbit Rocket Kafka Active 技术选型
Rabbit MQ:
理论:
单机吞吐量 万级,比RocketMQ,Kafka低一个级别
延迟最低,再微秒级,其他两个都是毫秒级
可用性策略:为了保持轻量级,用主从架构,其他两个都是分布式架构
消息可靠性:保证消息基本不丢,其他两个通过参数选择、优化配置可以做到0丢失
提供灵活的消息模型,例如Exchange模块提供的消息路由、动态队列…
实践:
提供可视化客户端,可不了解相关命令行指令进行管理
RabbitMQ提供了许多语言的客户端接口,比较友好
RabbitMQ本质还是维护一些管道,管道长度有限,无法应对消息堆积,只能曲线救国做点优化
曲线:增加消费者消费能力 / 将RabbitMQ无法消费的消息快刷到磁盘(使用惰性队列)
市面:
但是本身由erlang语言开发,为了并发能力,但国内少有erlang程序员,基于源码的debug和二次开发较为困难,只能依赖于开源社区,但社区无人担责
erlang语言和常规语言区别较大
原生支持并发性和分布式计算(COP:面向并发编程)
提供轻量级进程和消息传递机制,使得并发编程简单直观
代价:
erlang中变量不可变,一个变量仅仅是最一个值的引用,绑定后无法更改,只能通过新创建一个变量来实现变量值的变换
目的是面向并发编程,相当于最悲观的锁
Rocket MQ:
理论:
单机吞吐量10万级
可以支持几百 / 几千的topic,而kafka再topic到几百时吞吐量大幅度下降,kafka此时只能选择增加机器资源
基于分布式,有可扩展性和高可用,天生为了电商秒杀,实时数据分析场景使用
据说时延也是毫秒级
Java原生,中国人开发,易于阅读理解
缺点:国际生态不很好
要配合Flink,Spark进行流计算,但它们对RocketMQ的支持并不完备,不如Kafka
演进目标
消息基础架构的云原生演进【结合云原生浪潮下的生态技术,提高资源的利用率和弹性能力】
集成效率的优化【从API、SDK等多方面重构设计,对外提供能易用,更轻量级的方案】
事件、流集成场景的拓展【聚焦消息领域的后处理场景,消息的流式计算和轻计算】
架构:
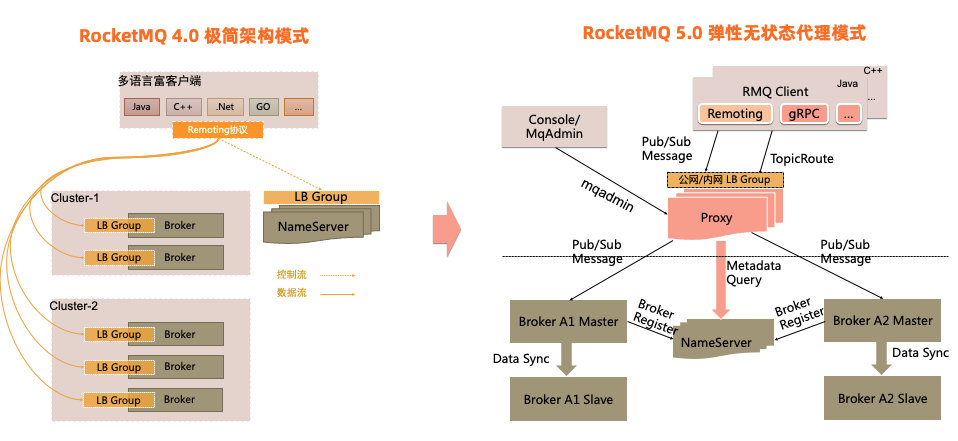
早期架构:
NameServer命名管理 本质是broker集群的注册中心 & 网关注册中心的作用是管理每个Topic的路由
网关的作用是将客户端的消息 / 请求路由到准确的服务器上
架构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
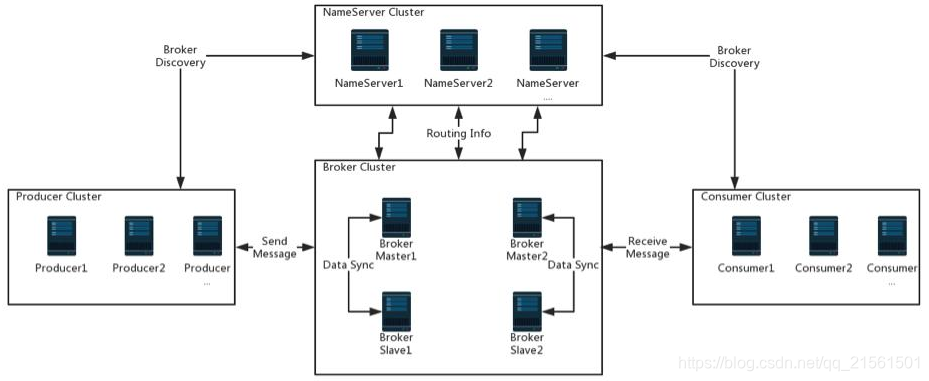
16生产者:首先和NameServer集群中随机一台建立长连接,
得知当前发送的Topic存在哪个Broker Master上,
然后再和Broker Master建立长连接
消费者:和NameServer集群中随机一台建立长连接,
得知当前想要消息的Topic存在那台Broker Master中
然后和Broker Master建立长连接
Broker:主从 + 集群
一个Master对应多个Slave,Master负责读写,Slave负责读取
Broker会定期上传心跳包:包括IP、Port、TopicInfo
【通过不同的配置文件选择模式】
- 两主
- 两主两从 异步复制
- 两主两从 同步复制
NameServer:关于Topic的路由注册中心,支持Broker的动态注册和发现
保存Topic和Broker的关系
也是Broker的生命注册中心
数据流转
1 | |
生产者发消息前,先向NameServer获取目标Topic的路由信息
NameServer中维护着Topic的路由表,已经Broker列表
路由表是一个map,key是Topic的名称,value是属于该Topic的Queue们分散在哪些Broker中的列表
Broker列表:用于管理一个主从架构下master和slave的注册信息,key是brokerName,value是又一个map,记录brokerId & Broker的地址
一个Topic下,Queue的存储为什么要分散在多个Broker中?
生产者根据某种Queue的选择策略,从Queue列表中选出一个Queue,准备发送
发送前对消息做一些压缩处理
发送
消息的消费:消费者从Broker获取消息的方式有pull拉 & push 推;消费者消费的模式有集群消费Clustering & 广播消费BroadCasting
拉:
实时性弱
推:
实时性高,典型的模式是发布订阅:
实现方式:某个Consumer在Queue上注册监听器(绑定回调函数,当Queue发现新的消息后触发回调,推送消息)
- 回调需要维护一个Consumer到Broker的长连接吗?
广播:
相同Consumer Group的每个Consumer都会收到同样的message
集群消费:
相同Consumer Group的每个Consumer中只有一个收到message
Key Point
1 | |
开源的可视化组件:rocketmq-console,用于控制台管理项目
本质就是一个【java-web项目】
页面 / 作用
集群管理:监控每个集群下主从节点的行为,比如生产的TPS、消费的TPS…
主题管理:对于每个主题的状态管理、路由管理…crud

默认主题有TopicTest,默认配置有4个队列(平行的四个队列用于防止单个的对头阻塞)
消息Message内容
绑定的主题
tag
值
消息主体内容
RocketMQ提供一种消息检索功能:根据topic、message key、messageID等条件搜索
使用【SpringBoot-starter】:

回来吧我的RocketMQ
特点:专为万亿级超大规模的消息处理而设计,具有高吞吐量、低延迟、海量堆积、顺序收发等特点
特性:事务消息、SQL过滤、轨迹追踪、定时消息、高可用多活等
设计原则:拥抱云原生
学习一个工具,从架构 & 功能 入手
架构
RabbitMQ中,队列的作用更偏向消费者,队列中元素的进入条件就是考虑了消费者的过滤条件,而RocketMQ中队列的作用更偏向于生产者,之后消费的过程再通过订阅关系中的tag过滤或者SQL过滤实现
RabbitMQ中,消息进入Broker和进入Queue中还有一层exchange,作用就是将消息准确推送进Queue中,也一定程度上实现了过滤;exchange的Topic模式能够兼容点对点和fanout模式;Topic模式下,每个队列绑定一个路由键,后续消息内也有一个路由键,只有当exchange匹配到消息的路由键和队列的路由键相符则进入Queue,队列的路由键使用模糊匹配来提高灵活性,当路由键是#或者*时,表示此队列会接收所有消息,当路由键没任何通配符,表示此队列直接收一种消息
而RocketMQ将消息投递到Queue时就很简单,指定Topic后就不管了,而是将消息过滤的能力交给消费者,通过订阅关系的tag过滤和SQL92过滤实现
功能
RocketMQ按照消息的类型实现特殊的需求
- 普通消息
- 顺序消息:可以将一个MessageGroup中的消息保证先后顺序
- 定时消息 / 延时消息:控制消息在一定时间内不能被消费
- 事务消息:RocketMQ支持的分布式事务消息
其他特性:每个都有背景 / 都是为了解决某些场景的问题
消息重试 & 流控机制
重试:
- 当客户端的请求由于网络故障、服务异常导致调用失败,为了保证消息的可靠性,客户端SDK中内置请求重试的逻辑
- 同步发送的重试:一次消息发送如果失败会一直占用线程资源进行重试,直到成功 / 超过最大重试次数
- 异步发送的重试:发起消息的线程后续还需要检查消息有无成功传递
问题:
重试就意味着一个消息多次发送,如果服务器本身没问题,只是响应事件超过阈值,就需要解决消息的幂等性问题
重试机制并不能保证消息一定发送成功,如果重试仍然失败则需要更强力的保障措施
重试最大的诟病就是资源占用太多
流控机制
- 当系统容量 / 水位过高,RocketMQ服务端会通过快速失败返回流控错误,从而避免底层资源承受过高压力
- 处理建议:
- 提前预防水位过高,通过可观测性功能监控,调整
- 如果当前MQ确实触发了流控,需要告知业务方替换到其他系统应急处理
- 当客户端的请求由于网络故障、服务异常导致调用失败,为了保证消息的可靠性,客户端SDK中内置请求重试的逻辑
消费者分类
RocketMQ 面向不同的业务场景提供了不同的消费者类型
场景中的因素
- 是否需要手动解决并发消费,如何通过并发消费提高消费速度
- 是否需要手动实现同步、异步消息处理
- 消费者处理消息时如何返回响应结果,正确处理返回正确结果,消息异常触发重试?从而确保消息可靠处理
消费者方面的数据流转:消息获取 –> 消息处理 –> 消费状态提交
类型
PushConsumer
高度封装,通过给Consumer设定监听器,监听器内绑定消费状态的回调函数,PushConsumer的SDK就会自动按照此逻辑完成回调
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20// 消费示例:使用PushConsumer消费普通消息。
ClientServiceProvider provider = ClientServiceProvider.loadService();
String topic = "YourTopic";
FilterExpression filterExpression = new FilterExpression("YourFilterTag", FilterExpressionType.TAG);
PushConsumer pushConsumer = provider.newPushConsumerBuilder()
// 设置消费者分组。
.setConsumerGroup("YourConsumerGroup")
// 设置接入点。
.setClientConfiguration(ClientConfiguration.newBuilder().setEndpoints("YourEndpoint").build())
// 设置预绑定的订阅关系。
.setSubscriptionExpressions(Collections.singletonMap(topic, filterExpression))
// 设置消费监听器。
.setMessageListener(new MessageListener() {
@Override
public ConsumeResult consume(MessageView messageView) {
// 消费消息并返回处理结果。
return ConsumeResult.SUCCESS;
}
})
.build();- 返回消费成功:return ConsumeResult.SUCCESS;
- 返回消费失败:return ConsumeResult.FAILURE;
simpleConsumer:封装性不高,可灵活自定义
实现绑定监听器的原理:
对于push的消费类型才需要确认消息是否需要重发,因为pull类型的确认都在消费者中完成,只需要保证消息正确到达即可- Consumer中维护一个缓存列表,记录本地消费的结果
- Server维护一个长轮询的线程,通过批处理的方式查看消费结果
消息过滤
MQ作为消息中间件被广泛应用于上下游的业务集成场景中,但实际同一个主题的消息往往会被多个不同的下游业务方处理,各下游的处理逻辑不同,需要消息过滤来保证下游业务方只关注自身逻辑需要的消息子集
两种过滤方式
- Tag标签过滤【基础过滤能力】
- SQL属性过滤【适合更加复杂的场景】
业务消息的拆分原本是基于Topic的,但是Topic中消息又需要被过滤,所以可以按照其中的tag进行更细粒度的拆分
但Topic这种资源比较重量级
消费者负载均衡
消费者的消费模式分为广播消费和共享消费
即:在一个消费者组中是全都获取消息,还是只有一个会获取到消息
负载均衡:
消费者组内有多个消费者共同承担消息消费任务,那么需要有一种分派逻辑决定谁消费
两种模式
- 消息粒度负载均衡
- 队列粒度负载均衡
消费进度管理
消费者刚启动时应该从哪里开始消费?如何感知某些信息已经被消费了?某消息消费后业务出现问题,该消息能否被重新消费?…
RocketMQ为每个consumer记录一个消费位点(Consumer Offset)【ThreadLocal】
消费重试
//TODO
消息存储和清理机制
//TODO
kafka:
理论:
最开始就是处理海量日志,导致特点是:性能最好,但无法保证消息不丢失
卡夫卡设计为一种 流式处理平台
具有的功能有:
消息队列
有持久化方案来容错【Kafka对持久化做了许多优化】
流式处理类库
快的原因:
异步 + 批量 + 压缩
持久化的磁盘IO也有优化,尽量不成为瓶颈
其他优化策略:零拷贝,pagecache…
一般配合大数据系统进行日志采集,实时数据计算…
高可用的实现方案:分布式 + 冗余数据
实践:
卡夫卡的生态圈十分完备,一旦Kafka推出新特性,整个大数据生态圈的技术站点,如Flink,Spark,Hadoop都会跟进
问题:
实现太过复杂
【异步 + 批量 + 压缩】完全基于异步,异步带来批处理,一批的数据压缩后当成一个数据传给消费者,但只适合数据量很大的场景,数据量假如很小,异步的特性完全没用【成也批量异步,败还没败】
早期Kafka重度依赖ZooKeeper做元数据管理和集群高可用,后期引入基于Raft的KRaft,简化了Kafka的架构【更轻】
1 | |